Today we faced an important issue with MySQL 5.5
Server stalled after aborting a TRUNCATE on a big table. Yes, this is bad to abort a TRUNCATE 😉 But this is not the issue I want to speak about. Server crashed, that’s a point. mysqld process restarted automatically, and started loading data into memory (massive use of InnoDB tables). This server has 128GB of memory, so buffer pool was set to 100GB (yes, that’s quite huge). Data set is ~ 100GB. After a few minutes, server crashed again, but this time complaining about memory.
Error log gave this :
*** glibc detected *** /usr/sbin/mysqld-5.5: malloc(): memory corruption: 0x00007f5ffc9affa0 ***
======= Backtrace: =========
/lib64/libc.so.6[0x7f7a46163e96]
/lib64/libc.so.6[0x7f7a46166b4e]
[...]
08:45:24 UTC - mysqld got signal 6 ;
The biggest problem is that this behaviour happened three times in a row. As it needs ~ 30 minutes to warm buffer pool, this was quite a downtime.
Memory usage looked like this (pink is pagecache) :
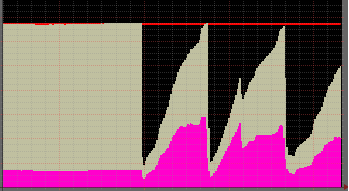
And dmesg reported this :
[28524726.820222] INFO: rcu_bh detected stall on CPU 32 (t=0 jiffies)
[28524726.820230] Pid: 53878, comm: mysqld-5.5 Not tainted 3.2.0-oxeva #8
[28524726.820237] Call Trace:
[28524726.820244]
[28524726.820285] [
[28524726.820301] [
[28524726.820314] [
[28524726.820329] [
[28524726.820337] [
[28524726.820341] [
[28524726.820350] [
[28524726.820365] [
[28524726.820367]
So RCU seems the one responsible for killing mysqld.
What is RCU ?
Let’s explain this in a few words : when you deallocate memory, the memory is not released immediately but marked as « can be deallocated ». The deallocation itself is asynchronous and handled by RCU.
(Well, this is a big shortcut, but if you’re interested, you can have full explanation here : http://www.rdrop.com/users/paulmck/RCU/whatisRCU.html)
So, what is happening here ?
When we have allocated all the memory (user space + page cache), and Mysql makes a malloc() to ask for more, kernel is faced to a dilemma : he has allocated 100%, but he knows some memory can be reclaimed. This is RCU job, but deallocation takes time, and malloc() needs to have an answer fast. This is a zone of undefined behaviour, and in our case, this results to a corruption with malloc() call (and mysqld crashed).
How can we fix this ?
As we have a majority of InnoDB tables, page cache is not very useful (innodb handles cache itself). So we can disable it by opening files with flag O_DIRECT.
This is handled with mysql variable innodb_flush_method
We launch mysql again with this variable set to O_DIRECT, and result is OK :
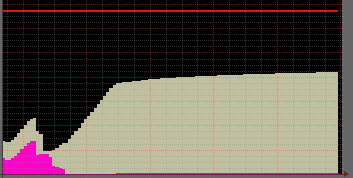
See ? No more pagecache used, and plenty of memory available.
We did not use O_DIRECT before because of incompatibilities with NFS, but this has been fixed since.